Distributed Ecommerce Scraper
Distributed Web Scraping System for Spacenets.tn
A Redis-Backed, Horizontally Scalable Scrapy Architecture
Author: Ibrahim Ghali
Project Type: Distributed Systems & Data Engineering
Target Website: Spacenets.tn
1. Introduction
Web scraping has become increasingly complex due to the widespread adoption of anti-bot and traffic analysis mechanisms by website owners. Modern websites employ multiple layers of protection such as IP reputation filtering, behavioral analysis, rate limiting, and fingerprinting techniques to distinguish between legitimate users and automated scrapers.
A major challenge arises when scraping systems are deployed on cloud hosting providers such as AWS, Google Cloud, or DigitalOcean. Requests originating from these infrastructures are often flagged or blocked, as legitimate end-users rarely browse the web from data centers.
This project presents a distributed web scraping architecture based on Scrapy and Redis, designed to efficiently scrape Spacenets.tn by distributing crawling workloads across multiple independent worker nodes while maintaining centralized coordination and state management.
2. Problem Statement
2.1 Limitations of Traditional Scraping Systems
Single-node or monolithic scrapers suffer from several limitations:
- Low scalability: Limited by CPU, memory, and network bandwidth of one machine
- Single point of failure: A crash stops the entire scraping process
- Predictable traffic patterns: Easy to detect and block
- Poor fault tolerance: No automatic recovery or continuation
- Operational rigidity: Difficult to scale dynamically
2.2 Hosting Provider–Based Scraping Issues
Scrapers deployed on cloud infrastructure face additional challenges:
- IP blocking due to known data-center IP ranges
- Shared IP reputation, where malicious users affect benign scrapers
- Unnatural traffic signatures compared to residential users
- High cost of residential proxies and VPN solutions
3. Proposed Solution
To address these challenges, this project adopts a distributed worker architecture built on the following principles:
- Decoupling request scheduling from execution
- Stateless scraping workers
- Centralized coordination using Redis
- Horizontal scalability
- Graceful failure handling
The system is based on the Producer–Consumer pattern, where URLs are centrally queued and consumed by multiple independent workers.
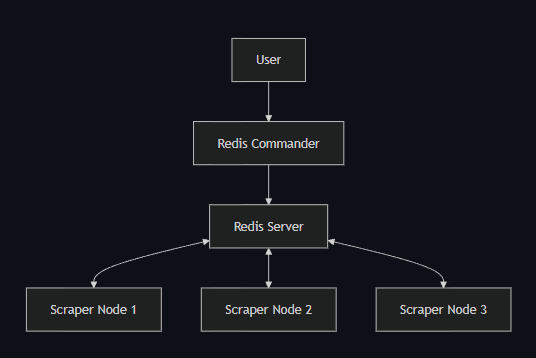
4. System Architecture Overview
4.1 Architectural Model
The system follows a Distributed Worker Architecture:
- A central Redis queue maintains crawl state
- Multiple Scrapy worker nodes fetch tasks from Redis
- Each worker independently processes pages
- Scraped data is stored centrally and exported after completion
This design ensures that workers do not need to communicate directly with each other, significantly reducing system complexity.

5. Core Technologies
5.1 Scrapy (Web Crawling Framework)
Scrapy is a high-performance Python framework for web crawling and data extraction.
Key Features Used:
- Asynchronous request handling
- Item pipelines
- Middleware hooks
- Configurable concurrency
- Robust error handling
In this project, Scrapy is responsible for:
- Fetching web pages
- Parsing HTML responses
- Extracting structured data
- Discovering new URLs
5.2 Scrapy-Redis (Distributed Crawling Extension)
scrapy-redis enables Scrapy to run in a distributed fashion using Redis.
🔗 https://github.com/rmax/scrapy-redis
Capabilities:
- Shared request queues
- Distributed URL deduplication
- Persistent crawl state
- Multiple concurrent workers
Instead of using Scrapy’s default in-memory scheduler, this system relies on Redis-backed queues, allowing multiple workers to operate on the same crawl without overlap.
5.3 Redis (In-Memory Data Store)
Redis is an in-memory data structure store used as the central coordination layer.
Roles in the System:
- URL queue (FIFO/LIFO)
- Duplicate request filtering
- Item storage
- Crawl progress tracking
Redis ensures:
- Atomic operations
- Low latency
- Safe concurrency between workers
5.4 Docker (Containerization Platform)
Docker is used to package and deploy the system components.
Benefits:
- Environment consistency
- Easy replication of workers
- Simplified deployment
- Isolation between services
Each worker runs in a container, making it trivial to scale the system horizontally.
5.5 Docker Compose (Service Orchestration)
Docker Compose orchestrates the multi-container setup.
🔗 https://docs.docker.com/compose/
It manages:
- Redis service
- Multiple Scrapy worker containers
- Redis Commander UI
5.6 Redis Commander (Monitoring Interface)
Redis Commander provides a web-based interface to inspect Redis data.
🔗 https://github.com/joeferner/redis-commander
Used for:
- Viewing queued URLs
- Monitoring scraped items
- Debugging crawl behavior
- Verifying system state
6. Data Flow and Execution Process
6.1 Workflow Steps
- Initialization
- Redis server is started
- Worker containers are launched
- URL Seeding
- Initial URLs are pushed into Redis
- Redis becomes the single source of truth
- Distributed Crawling
- Workers fetch URLs from Redis
- Pages are downloaded and parsed
- New URLs are added back to Redis
- Item Processing
- Extracted data is validated and structured
- Items are stored centrally
- Monitoring
- Crawl progress is observed via CLI tools and Redis Commander
- Data Export
- Final data is exported to structured formats (JSON)
7. Scalability Characteristics
7.1 Horizontal Scalability
The system scales by adding more workers, not by modifying code.
- N workers → ~N× throughput
- No coordination overhead
- No duplication of work
7.2 Fault Tolerance
Failure Scenario
System Behavior
Worker crash
Other workers continue
Network error
Request retried
Partial crawl
Resume from Redis
Duplicate URL
Automatically filtered
8. Anti-Bot Considerations
While this project does not directly bypass anti-bot systems, it is designed to support:
- Request throttling
- User-agent rotation
- Proxy integration
- Session management
- Headless browser extensions
The architecture ensures these strategies can be added without redesigning the system.
9. Ethical and Legal Considerations
- Respect for
robots.txtdirectives - Rate limiting to avoid server overload
- Educational and research-focused usage
- No intent to bypass authentication or private content
10. Use Cases
- E-commerce product monitoring
- Market intelligence
- Academic research
- Distributed systems experimentation
- Data engineering pipelines
11. Conclusion
This project demonstrates a real-world distributed web scraping system built using industry-standard tools. By combining Scrapy, Redis, and Docker, the system achieves:
- High scalability
- Fault tolerance
- Modular design
- Operational flexibility
The architecture aligns with modern distributed system principles and provides a solid foundation for advanced scraping and data ingestion platforms.
12. References
- Scrapy Documentation
https://docs.scrapy.org/ - Scrapy-Redis GitHub Repository
https://github.com/rmax/scrapy-redis - Redis Official Documentation
https://redis.io/docs/ - Docker Documentation
https://docs.docker.com/ - Docker Compose Documentation
https://docs.docker.com/compose/ - Redis Commander
https://github.com/joeferner/redis-commander - Distributed Systems Concepts
https://martinfowler.com/articles/patterns-of-distributed-systems/